







Turning raw data into actionable insights unlocks high performance for sales and marketing teams — a competitive edge that grows as customer expectations evolve and go-to-market strategies become more complex.
The first step? Making sure your data is reliable.
Maintaining strong data quality requires continuous cleaning and correcting. Scott Taylor, a consultant and author known as “the Data Whisperer,” puts it this way: “Good decisions made on bad data are just bad decisions you don’t know about yet.”
For modern data teams, the answer lies in enriching their databases with the most reliable information and preventing errors from entering the system in the first place.
Here’s how to ensure your go-to-market teams have the high-quality data that will set them apart from the competition.
What is Data Quality?
In a business context, data quality refers to the accuracy, completeness, and accessibility of data collected and stored by a company. Data quality is measurable, and it can significantly impact the efficiency of a business.
High quality data accurately reflects the real-world events or entities it represents, which means the information can be trusted for reporting, analytics, and decision-making.
Data Quality Management
Maintaining high data quality is an ongoing task. Information that is correct today can easily become outdated tomorrow — and that’s assuming every record was perfect to start with.
Data quality management involves creating guidelines for data collection, standards for storage, and rules to ensure accuracy and reliability. It includes techniques like data profiling, auditing, cleansing, and monitoring.
While these processes can help any business, they take on greater importance as the volume of data grows. Without a system in place, data quality can decrease rapidly.
In contrast, good data management ensures that everyone in the company has information they can rely on. This trust is the foundation for fact-based decision making.
Why Problems With Data Quality Can Be Costly
Bad data causes big problems — and costs businesses a lot of money. According to Gartner, the missed opportunities and added technical hurdles of poor quality data cost larger businesses an average of $12.9 million per year. What’s more, data scientists spend up to 40% of their time manually cleaning datasets.
To get the most out of business data, people and processes must be able to act on it quickly. But it’s impossible to transform data into actionable insights at scale without high-quality data.
The Dimensions of Data Quality
Data quality has multiple dimensions. Business leaders who wish to improve data governance need to consider the following:
- Completeness: Each record should contain the minimum company, contact, and behavioral information required for successful engagement.
- Accuracy: Data must be factually correct and properly represented to be used in the decision-making process.
- Validity: Any data collected should be formatted for use in your current processes. Data should also follow business rules, and conform to relevant legal requirements.
- Consistency: Information of the same type should be formatted in the same way. For example, do you store direct-dial numbers with or without the international code?
- Uniqueness: Duplicated data can invalidate business intelligence, and storing it is a waste of resources.
- Timeliness: Big data is only useful if your team can access insights in a timely way.
An assessment that includes all these dimensions provides a good snapshot of your data quality. However, the picture can change quickly.
This is partly because data is rarely left untouched. Salespeople are constantly accessing customer data. Automation tools draw on database records to complete tasks. Executives need the latest information to make decisions.
Over time, those processes can interfere with data consistency and accuracy — otherwise known as data integrity. To prevent these problems, it’s essential to have management and maintenance processes throughout the data lifecycle.
Data Quality Measures
While the dimensions mentioned above are important, overall reliability is calculated by combining a different (but related) set of metrics:
- Match Rate: The percentage of records in a dataset that can accurately be linked or matched to a corresponding record. A good score means consistent data and good mapping.
- Fill Rate: The ratio of populated (or non-null) data values in a dataset compared with the total possible values for a given field. A high rate means there is minimal missing information.
- Match Confidence: The level of certainty that a matched record is the right one, usually expressed as a score or percentage. A high score indicates high confidence.
By multiplying data quality characteristics, you can calculate a dataset’s reliability rating, or how trustworthy it is.

The Recipe for Better GTM Data Maintenance
Even in the most data-aware companies, reliability is rarely perfect. What’s more, the majority of businesses miss this mark.
Maintaining good data quality is even harder when drawing information from multiple sources. Thankfully, there’s a clear path to improving GTM data quality through smart orchestration:
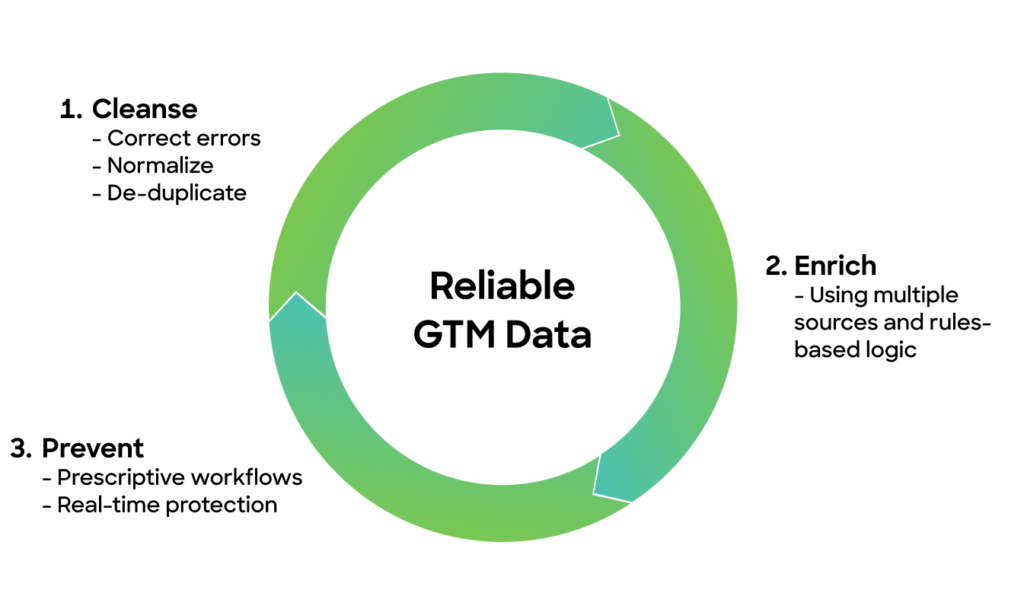
1. Cleanse: A data normalization (or data standardization) process is necessary for data that enters a system through various touchpoints.
This process groups similar values into one common value for streamlined processing, distributing, and analysis. Data normalization is necessary because it provides semantic consistency across your GTM systems.
In addition, the data cleansing step (a.k.a. remediation) can involve correcting inaccuracies, such as spelling mistakes in data records, and removing duplicate data to free up resources.
2. Enrich: Enriching data ensures that each field has the most reliable information. It also expands the amount of information you can access, enabling more sophisticated customer segmentation.
Multi-vendor enrichment sources thousands of data points from a variety of third-party vendors. No data provider has the perfect database, so consider using multiple data providers to build a single source of truth.

3. Prevent: The “1–10–100 rule” explains that it costs 10 times more to correct an error than to prevent one, and 100 times more if an error is not fixed. This illustrates the need to prevent data errors from the beginning.
Proper data orchestration can automatically merge or convert leads, contacts, and accounts based on matching rules that you define.
Security is another consideration here. Adopting secure practices can prevent tampering, meaning your teams can place more confidence in the reliability of your data. This is particularly important when you’re gathering data from multiple sources, and relaying the information between different platforms.
Embracing Master Data Management (MDM)
It’s worth noting that processes are not a replacement for culture and strategy. Master data management (MDM) is a framework that can shape business policy to prioritize data quality.
We previously mentioned some key elements of MDM, including data normalization and error correction. Here are more initiatives associated with MDM:
- Data Profiling: Running a comprehensive analysis of data structures can reveal potential deficiencies and opportunities for improved integrations.
- Data Stewards: Assigning personal responsibility for data quality to select individuals ensures someone is always focused on the task.
- Data Governance: Enacting policies and rules to manage data quality, data privacy, and compliance maintains standards across teams.
- Data Distribution: Ensuring that data is available to the appropriate systems, applications, and individuals within the business.
These proven practices lift data quality over time and make stored data more useful.
The Benefits of Improved Data Quality Management
Businesses that improve their information management avoid the costs associated with bad data quality and build a culture around data maintenance and governance, which can unlock major benefits across all verticals.
Smarter Business Decisions
Looking after data means teams can access real-time data analytics and set up dashboards, which can foster better leadership decisions. Well-organized data is also essential for building AI tools that can provide predictive intelligence for go-to-market teams.
Better Informed Stakeholders
Improved data maintenance gives stakeholders access to consistent and accurate data, informing and aligning them on business goals. The same goes for performance: data transparency makes it easier to track marketing KPIs.
Enhanced Supply Chain Management
For businesses with a supply chain, effective data handling permits real-time operations tracking, including inventory levels, order statuses, and vendor performance. This makes it easier to respond quickly to changes in demand and other external factors.
Better Sales and Marketing With Multi-Vendor Enrichment
At the enterprise level, companies need access to many data sources to perform the targeted sales and marketing activities that drive revenue and growth. A typical enterprise uses over a dozen different data sources.
Onboarding this much data is a complex, time-consuming operation, in part because vendors sell their data in varying formats and taxonomies. To handle these variations in larger data quality management strategies, multi-vendor enrichment is important. It allows businesses to find, integrate, and orchestrate this third-party data into CRM systems and related tools.
Through flexible rules-based logic, multi-vendor enrichment standardizes and segments data according to a group’s unique business requirements. Companies can complement ZoomInfo data and other vendor data with niche datasets to get granular, targeted audience-building info to cover every inch of their total addressable market.

Most data quality management solutions require multiple tools to clean, normalize, transfer, enrich, and match data — each adding complexity. A centralized solution decreases the need for disparate tools, simplifying GTM data maintenance efforts.
ZoomInfo OperationsOS delivers an integrated data quality management system that eliminates the time-consuming and expensive task of manually cleansing, enriching, and activating multiple datasets.
With multi-vendor enrichment, revenue operations teams can build engagement-ready data in one click, rather than spending hours in spreadsheets. Whether through self-service enrichment tools or a more tailored option, ZoomInfo curates the world’s best business data for your team.